固定長ファイルをエクセルに変換するマクロをVBAで開発(応用編)

SE・情シス担当歴20年のコウノです。
前回、固定長ファイルをエクセルにインポートするマクロを解説しました。今回は、その応用編になります。
固定長のファイルでデータをやり取りする際は、「この行は何の行か」を表すコード(レコード区分やデータ種別と呼ばれます)が入っています。つまり、行によってデータのルールが異なることが一般的で、これがデータの解析の難易度を押し上げています。
そこで、今回はレコード区分によってデータレイアウトの定義が異なるタイプの固定長ファイルを扱えるように、前回ご紹介したマクロをグレードアップしてみたいと思います。
仕様
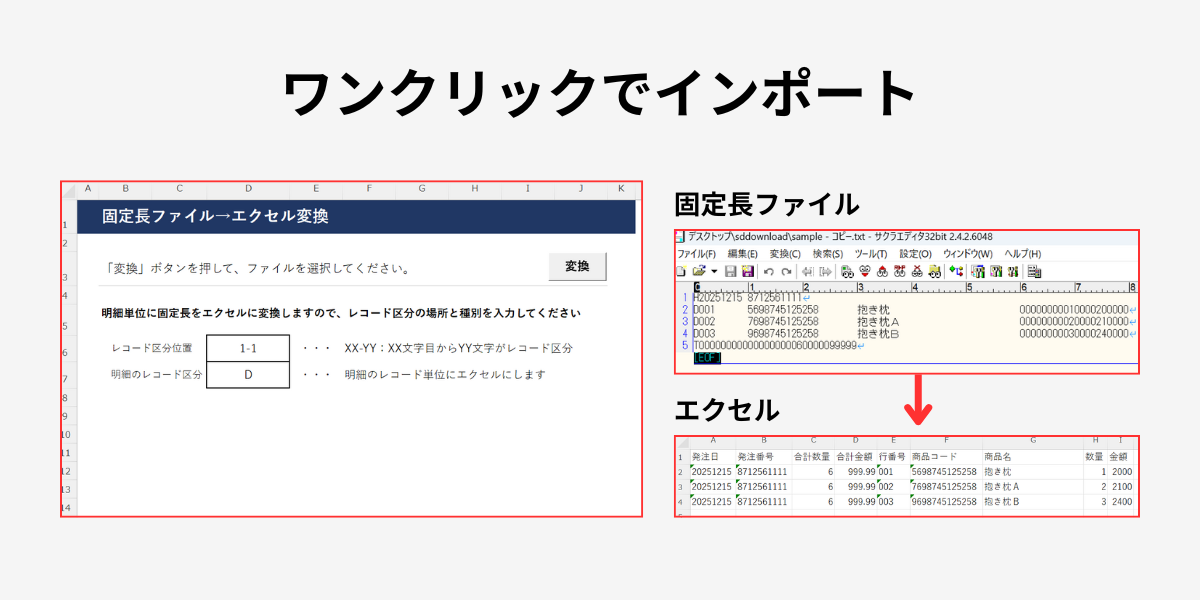
- 切り取る項目、位置・文字数(バイト数)、レコード区分を利用者が事前に設定シートに定義しておく
- マクロの実行ボタンを押下すると、インポートするファイルを選べるようになる。
- 選んだ固定長ファイルを設定シートに記載した定義に従い、1行ずつエクセルに転記する
- 変換したデータは、新規のエクセルファイルとして保存する
固定長ファイルは、レコード種別により、項目のレイアウトが異なることが一般的です。
- ヘッダー部
- 明細部
- トレーラー部
明細単位でデータを確認したいケースがほとんどだと思いますので、明細単位でエクセルに出力します。その際に、ヘッダー部やトレーラー部に存在する情報も付与します。
VBAサンプルコード:レコード区分がある固定長をエクセルにインポートする
ポイント
HOMEシート
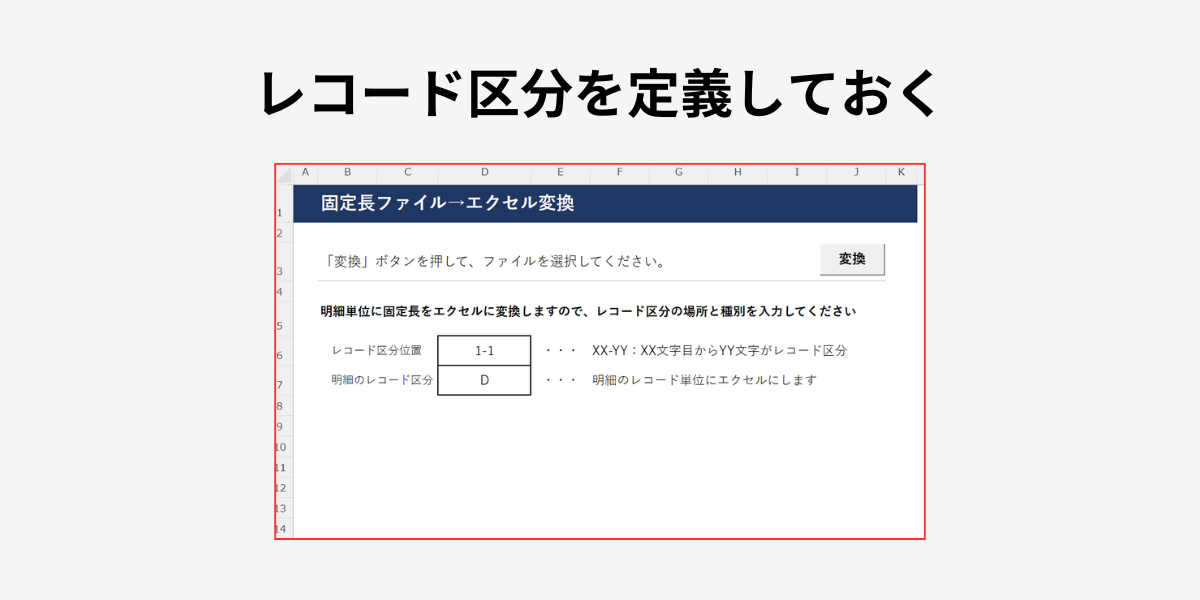
レコード区分の位置と明細部となるレコード区分の値を指定します。
取得する項目、開始位置、バイト数を予め指定しておきます。
設定シート
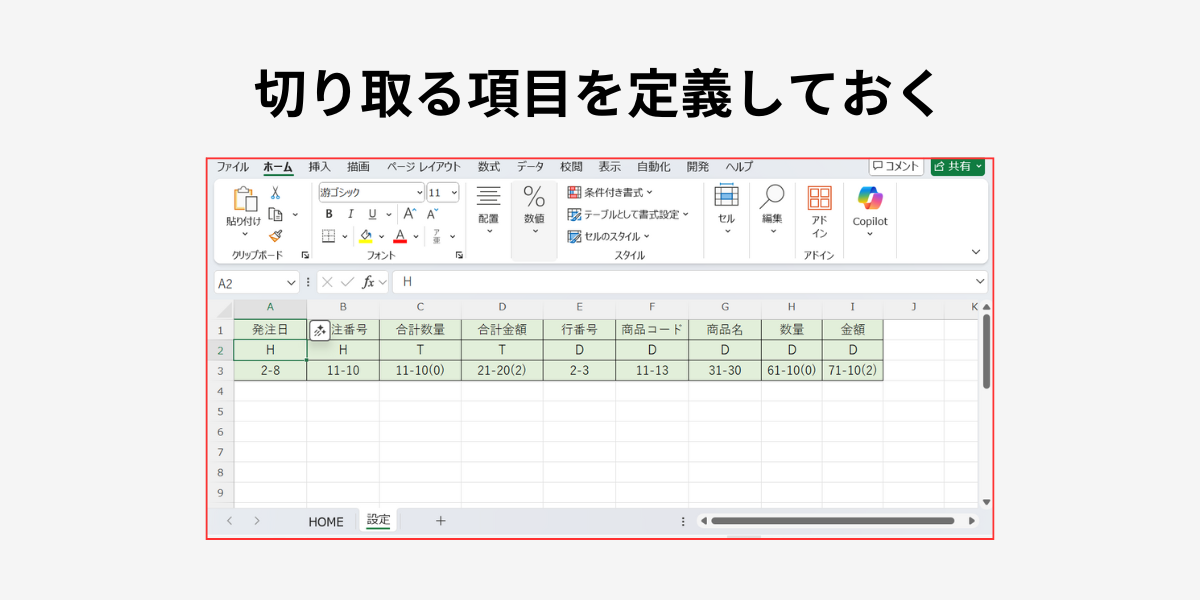
設定シートの書き方
- 1行目・・・切り取った値の項目名を定義します。
- 2行目・・・レコード区分の値
- 3行目・・・開始位置と切り取り文字のバイト数(例.3-10)
- 3-10の場合、3バイト目から10バイト切り取るという意味です
- 数値型にしたい場合は、「3-10(3)」のように小数点以下の桁数をカッコで追記します
固定長ファイルを扱うことが多い業界・業務例
- 金融・経理(全銀フォーマット)
- 最も代表的な例です。業務: 銀行への給与振込データの送信、口座振替データの受信など。
具体例: 日本の銀行間データ通信(全銀システム)は、1レコード120バイトの固定長が標準です。経理担当者が、システムから吐き出された「振込結果データ(固定長)」をこのマクロでエクセルにし、消込作業を行う、といった用途に最適です。 - 物流・小売(EOS/EDIデータ)
- 業務: 受発注データのやり取り。
具体例: 大手スーパーやコンビニチェーンと卸売業者の間で行われるデータ交換(JCA手順など)では、昔から固定長が使われています。「商品コード(13桁)+数量(5桁)+店舗コード(6桁)…」といった長い数字の羅列が送られてくるため、これを人間が見やすいエクセル伝票に変換するのに使われます。 - 自治体・官公庁
- 業務: 住民税データ、レセプト(医療明細)データなど。
具体例: 自治体の基幹システムは非常に堅牢な古いシステムが多いため、他システムとの連携用に固定長ファイルが吐き出されることがよくあります。 - システム開発の現場
業務: テストデータの検証。 - 具体例: 開発者が「COBOLで書かれたプログラムが出力した結果が正しいか」を確認する際、テキストエディタで文字数を数えるのは大変です。このマクロでエクセル化し、計算や検索をしやすくして検証します。
- CSV:
2025/12/15,みかん,100(カンマで区切る) - 固定長:
20251215みかん 0000000100(位置と長さで決まる) - 数値項目: 通常は 「前ゼロ埋め」 です。
- 10桁の枠に100円を入れる →
0000000100 - ※稀にスペース埋めの場合もあります。
- 10桁の枠に100円を入れる →
- 文字項目: 通常は 「後ろスペース埋め」 です。
- 10桁の枠に"ABC"を入れる →
ABC - ※全角文字(日本語)が入る場合は、全角スペースで埋めるか半角スペースで埋めるかの仕様確認が必須です。
- 10桁の枠に"ABC"を入れる →
- 半角文字(数字・英字): 1文字 = 1バイト
- 全角文字(漢字・ひらがな): 1文字 = 2バイト
1またはH: ヘッダー(Header)2またはD: データ(Data)8またはT: トレーラー(Trailer)9: エンドレコード(End)- データ量が予測できる: 1件100バイトと決まっていれば、1万件なら必ず100万バイトになります。昔のコンピュータにとって、これはメモリ管理がしやすく非常に重要でした。
- 高速処理: 「カンマを探す」という処理が不要で、「先頭から何バイト目」とピンポイントで読み書きできるため、超大量データの処理が高速です。
- 堅牢性(データの壊れにくさ): 1行の長さが厳密に決まっているため、もし1バイトでもズレていれば「ファイルが壊れている」と即座に検知できます(CSVだとズレていても気づきにくい)。
固定長ファイルを扱うときによくあるルール
ヘッダー、明細(データ)、トレーラーという「階層構造」以外にも、固定長ファイルには**CSVやExcelとは決定的に違う「独特のルール」**がいくつかあります。これらを知っておくと、「なぜVBAであのような処理(バイト変換など)が必要だったのか」がより深く理解できます。
「区切り文字」がない(定規で測る世界)
CSVはカンマ(,)が列の区切りですが、固定長ファイルには区切り文字が一切ありません。「1文字目から10文字目までは日付」「11文字目から20文字目までは金額」というように、**あらかじめ決められたバイト数(長さ)**だけが頼りです。
「パディング(埋め)」のルール
決められた長さ(例:10桁)に対して、実際のデータ(例:100円)が短い場合、隙間を何かで埋める必要があります。これを「パディング」と呼びます。
バイト数と文字コード(Shift-JISの壁)
日本の固定長ファイル(全銀協フォーマットなど)は、歴史的な背景から**Shift-JIS(シフトジス)**という文字コードで作られていることがほとんどです。
ここが最大の難所です。「あ」は1文字ですが、コンピュータ上の容量は2バイト(半角2文字分)を使います。
「10バイト切り取る」という指示があったとき、文字数で数えてしまうと、全角文字が混ざったときに位置がズレてしまいます。
レコード区分(行の役割を決める合図)
データの内容を識別するために、行の**特定の場所(多くは先頭1桁目)**に、「この行は何の行か」を表すコードが入っています。
システムはこの1文字だけを見て、「あ、次は明細行が来るな」「お、合計行が来たぞ」と瞬時に判断して処理を切り替えます。
なぜ今でも使われているのか?(メリット)
ExcelやCSVの方が人間には見やすいですが、銀行や企業の基幹システムでは今も固定長が主役です。
エクセルを活用して業務改善する方法
本記事では固定長ファイルをエクセルに変換するマクロの作り方を解説しました。エクセルを活用して業務を効率化する方法はたくさんあります。もっと知りたいというかたは、以下のフォームからお問い合わせください
